2022年2月15日,《国防建模与仿真:应用、方法和技术》杂志刊发了由Paul K Davis和Paul Bracken合作的一篇论文《基于兵棋推演建模行为的人工智能》(Artificial Intelligence for Wargaming and Modeling)。

关于作者
保罗·k·戴维斯(Paul K. Davis)是兰德公司的兼职首席研究员,也是帕迪·兰德研究生院的政策分析教授。他的研究兴趣包括战略规划及其改进方法、决策理论、威慑理论、反恐、先进的分析、建模和博弈方法,以及异质信息融合。他撰写或与他人合著了广泛阅读的书籍,涉及国防规划、基于能力的规划、组合分析、威慑和影响理论,以及一篇关于反恐社会科学的综合评论。在加入兰德公司之前,戴维斯是美国国防部的高级主管。

保罗·k·戴维斯(Paul K. Davis)曾任职于国防部、国家科学院和情报机构的多个国家小组;他也是一些专业期刊的定期评论员。戴维斯在密歇根大学安娜堡分校获化学学士学位,在麻省理工学院获得理论化学物理学博士学位。
关于本文
论文摘要
本文中,我们讨论了如何将人工智能(AI)用于政治-军事建模、仿真和兵棋推演,针对与拥有大规模杀伤性武器和其他涉及太空、网络空间和远程精确武器的高端能力的国家之间的冲突。人工智能应该帮助兵棋推演的参与者和仿真中的智能体,理解对手在不确定性和错误印象中行动的可能视角、感知和计算。人工智能应该认识到升级导致无赢家的灾难的风险,也应该认识到产生有意义的获胜一方和落败一方结果的可能性。我们将讨论使用几种类型的AI功能对建模、仿真和兵棋系列的设计和开发的影响。在使用或没有使用人工智能的情况下,通过理论和使用仿真、历史和早期兵棋推演的探索工作,讨论了基于兵棋推演的决策辅助。
关键词
人工智能、兵棋推演、建模和仿真、认知建模、决策、深度不确定性下的决策、大规模方案生成、探索性分析和建模
论文架构
1.引言
在本文中,我们认为
(1)建模、仿真和兵棋推演(MSG)三者是相关联的研究方法,应当共同使用;
(2)人工智能(AI)可以为每个研究方法做出贡献;
(3)兵棋推演中的AI应该由建模和仿真(M&S)提供信息,而建模和仿真(M&S)中的AI应该由兵棋推演提供信息。
我们概述了一种方法,为简洁起见,重点是涉及拥有大规模毁灭性武器(WMD)和其他高端武器的国家的政治-军事建模、仿真和兵棋推演(MSG)。第2节提供了我们对建模、仿真和兵棋推演(MSG)和分析如何相互联系的看法。第3节通过研究20世纪80年代的系统来说明这一点是可行的。第4节提出今天的挑战和机遇。第5节简述了结构的各个方面。第6节强调了在开发人工智能模型和决策辅助工具方面的一些挑战。第7节为研究结论。
在本文中,我们用“model”(模型)来涵盖从简单的数学公式或逻辑表到复杂的计算模型的范围;我们用“wargame(兵棋)来概括从小型的研讨会练习(例如Day-After练习)到大型的多团队参与的较长时间的兵棋推演。
2.建模、仿真、推演和分析的集成视角
建模、仿真和兵棋推演(MSG)可以用于广泛的功能,如表1所示。每种功能都可以由每个建模、仿真和兵棋推演(MSG)元素来解决,尽管相对简单的人类活动,如研讨会兵棋和Day-After练习已被证明对后两个主题具有独特的价值。

通常形式的建模和仿真(M&S)和兵棋推演有不同的优势和劣势,如表2前三栏中的定型。建模和仿真(M&S)被认为是定量的、严格的和 “权威的”,但由于未能反映人的因素而受到严重的限制。建模和仿真(M&S)的批评者走得更远,认为建模和仿真(M&S)的 “严格” 转化为产生的结果可能是精确的,但却是错误的。在他们看来,兵棋推演纠正了建模和仿真(M&S)的缺点。建模和仿真(M&S)的倡导者则有不同的看法。

我们确实认识到并长期批评了正常建模的缺点。我们也从兵棋推演中受益匪浅,部分是通过与赫尔曼-卡恩、兰德公司和安德鲁-马歇尔的长期合作,但兵棋推演的质量从浪费时间甚至起反作用到成为丰富的洞察力来源。虽然这种见解在没有后续研究的情况下是不可信的,但来自建模的见解也是如此。
我们本文的一个论点是,这种刻板印象不一定是正确的,我们的愿望应该是表的最后一栏–“拥有一切”,将建模、仿真和推演整合在一起。图1显示了一个相应的愿景。
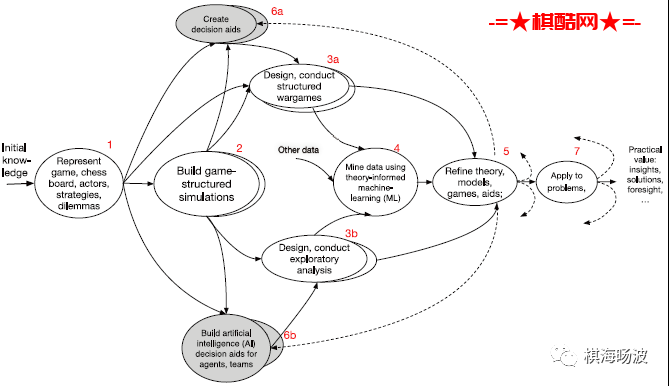

这种理想化的活动随着时间的推移,从研究、兵棋推演、军事和外交经验、人类历史、人类学等方面开始(第1项),汇集关于某个领域(例如印度-太平洋地区的国际安全问题)的知识。这就是对棋盘、行动者、潜在战略和规则的确定性。
两项工作的进行是不同步的。如图1的上半部分,兵棋推演在进行中,为某种目的而结构化。无论图中的其他部分是否成功执行,这都可能独立发生。同时,建模和仿真(M&S)以游戏结构化模拟的形式进行。随着时间的推移,从建模和仿真(M&S)和兵棋推演中获得的经验被吸收,使用AI从建模和仿真(M&S)实验中挖掘数据(第4项),以便为后续周期完善理论和数据(第5项)。在任何时候,根据问题定制的建模、仿真和兵棋推演(MSG)都会解决现实世界的问题(第7项)。如同在浅灰色的气泡中,人类团队的决策辅助工具(项目6a)和智能体的启发式规则(项目6b)被生成和更新。有些是直接构建的,但其他的是从分析实验和兵棋推演中提炼出来的知识。有些智能体直接加入了人工智能,有些是间接的,有些则根本没有。
图1鼓励MSG活动之间的协调,尽管这种协调有时可能是非正式的,可能只是偶尔发生。图1的意图可以在一个单一的组织中完成(例如,敏感的政府内工作)和/或在智囊团、实验室、私营企业、学术界和政府中更开放的持续努力计划中完成,就像图2中的DARPA研究称为社会行为建模实验室(SBML)。在任何一种情况下,这种方法都会鼓励多样性、辩论和竞争。它也会鼓励使用社区模块来组成专门的建模、仿真和兵棋推演(MSG)综合组件。这与专注于一个或几个得天独厚的单一模型形成鲜明对比。直截了当地说,这个愿景是革命性的。
3.存在证明
图1设想的灵感来源于20世纪80年代的兰德公司战略评估系统(RSAS)(附录1指向文件)。为了响应国防部关于更好地利用兵棋推演进行战略分析的要求,由Carl Builder领导的兰德公司团队提出了自动化的兵棋推演,它将利用那个时代的人工智能、专家系统,但这将允许可互换的人工智能模型和人类团队。这导致了一个多年项目,我们中的一个(P.K.D.)在1981年加入兰德公司后领导了这个项目。
4.挑战与机遇
4.1 国家安全挑战
4.1.1多极化和扩散
4.1.2多维战争
4.1.3有限战略战争的可行性
4.1.4盟友和伙伴之间的目标冲突
4.2技术挑战与机遇4.2.1基于智能体的建模4.2.2人工智能4.2.3网络化4.2.4模块化和特制的模型构成4.2.5数据驱动的人工智能/机器学习
4.2.6深度不确定性下的决策
5.体系架构
5.1功能要求

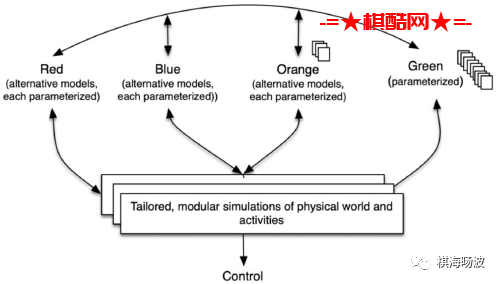
5.2在巨大的不确定性和分歧中进行探索性分析的局限性
6.决策辅助和人工智能
6.1兵棋推演的决策辅助功能6.1.1通用功能
6.1.2决策辅助的近期目标
6.1.3人工智能增强决策辅助的长远目标
6.2兵棋推演的决策辅助功能
6.2.1模拟是否足够丰富,足以代表基本的复杂性?
6.2.2从大量的方案中提取见解
6.2.3从大量的数据收集中提取见解6.3认知AI和相关决策辅助的问题

7.结论和建议
附录
参考文献
我们在遵照全文的基础上,也对本文进行了翻译整理,获得报告全文,欢迎关注“棋海旸波”公众号。
原版报告全文下载,请关注公众号,回复“兵推建模行为”下载。
全称:《Artificial Intelligence for Wargaming and Modeling》



